The data is sample measurements taken from the radio frequency spectrum between 70e6-hertz and 6e9-hertz. It was sampled with about 16 8-msps baseband measurements and each of these were broken into 40 200-khz samples. A spectral mask was applied to normalize the 200-khz channels across the baseband. The data was pulled from multiple boards so there is some unknown amount of noise in the data due to the boards potentially having some differences in magnitudes due to the front ends. There is one improvement that could be made to the data.
One way the data could be improved is by calibrating each sample source. This would require hooking each board to a known source, which I have, and then building a normalization over frequency so each board reports as close to the same magnitude as possible. The format of the data is also interesting.
The data uses a sequential Python pickle format. And each pickle object contains one set of 200-khz samples from one source along with a timestamp, source identifier, and a few other attributes such a sampling rate. An example of a sample entry is found below.
format = {
'time': unix_time_seconds_float,
'freq': frequency_in_hertz,
'b0': baseband_antenna_rx0_mean_magnitude,
'b1': baseband_antenna_rx1_mean_magnitude,
'bw': bandwidth_in_hertz,
'sps': sampling_rate_in_hertz,
'channel': [
{
'freq': local_frequency_offset,
'b0': channel_rx0_mean_magnitude,
'b1': channel_rx1_mean_magnitude,
},
# ... 39 more channel measurements
]
}The data is currently being stored in an Amazon S3 bucket. It is stored in roughly 4MB files which are named using the format below:
uid = uuid.uuid4().hex
creation_time = time.time()
oldest_entry_time
newest_entry_time
(uid, creation_time, oldest_entry_time, newest_entry_time)I’ve prepared for processing more data than RAM can hold because I hope to collect a lot of data. This required modification of the algorithms and some loss of performance. The type of data store was also important to figure out.
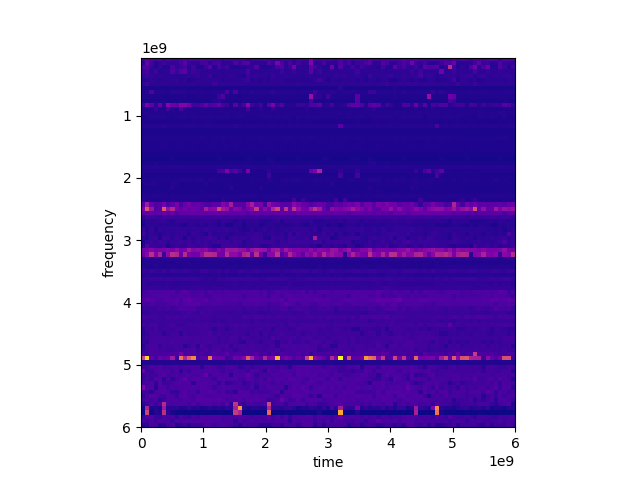
I was trying to figure out if this collection of data was a data lake or a data warehouse. I’ve come to the conclusion it best fits the definition of a data lake because it consists of data stored in its natural/raw format.
The end goal of the data store is to realize the radio frequency environment around me and secondarily it provides the opportunity to test cloud services like Amazon S3, EC2, and Kubernetes.